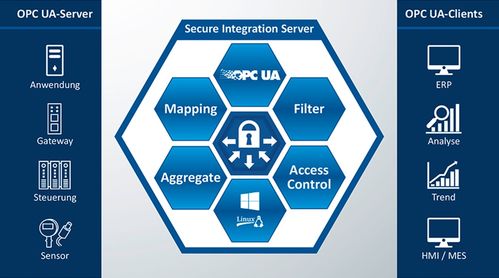
在上一部分探讨了海量数据处理系统的核心挑战与基础理念后,我们将视角深入阿里巴巴内部实践,剖析其数据处理系统的架构演进与创新服务。这些源自实战的架构思想与服务模式,不仅支撑了阿里经济体庞杂的业务,也深刻影响了业界数据处理技术的发展方向。
一、 核心架构的迭代与分层解耦
阿里海量数据处理系统的架构演进,清晰地体现了一条从“集中式、定制化”到“平台化、服务化”,再到“云原生、智能化”的路径。
- 计算存储分离与统一调度层:早期系统常采用计算与存储紧耦合的模式(如早期的Hadoop集群),存在资源利用率不均、扩缩容不灵活等问题。阿里通过构建如MaxCompute、Flink等系统,实现了计算与存储的彻底分离。计算资源由统一的资源调度系统(如伏羲)进行管理,存储则依托于高可靠、高可扩展的分布式文件系统(如盘古)。这种分离架构使得计算资源可以按需弹性伸缩,独立优化,并能够对接多种数据源,形成了强大的数据处理底盘。
- 流批一体与统一数据开发:传统Lambda架构需要维护实时和离线两套代码与链路,复杂度高。阿里内部推动的Blink(Flink阿里内部版本) 及后续的实时计算Flink版,率先实现了流批一体的计算引擎。这意味着开发者可以用同一套API和语义同时处理实时流数据和历史批量数据,大幅降低了开发和运维成本。在数据开发层,DataWorks作为一站式数据开发与治理平台,提供了从数据集成、开发、调度到运维、安全、质量的全链路可视化服务,将复杂的分布式处理任务简化为平台上的配置与拖拽操作。
- 湖仓一体与数据资产管理:随着数据量激增和数据应用多样化,单纯的数据仓库或数据湖模式均显不足。阿里通过推进湖仓一体架构,将数据湖的灵活性、丰富数据格式支持与数据仓库的企业级治理、高性能分析能力相结合。底层是开放的数据湖存储(如OSS),之上构建高效的数据仓库分析能力(MaxCompute),并通过DataWorks的数据地图、数据质量、数据血缘等功能,实现数据的全生命周期管理和资产化运营,确保数据可用、可信、可管。
二、 数据处理服务的创新与产品化
基于稳健的底层架构,阿里将数据处理能力封装成一系列高效、易用的服务,赋能内外业务。
- 交互式分析服务:AnalyticDB与Hologres:为应对海量数据下的实时交互查询与多维分析,阿里自主研发了AnalyticDB(ADB) 和 Hologres。它们采用MPP(大规模并行处理)架构、向量化执行引擎、智能索引等技术,实现了对万亿级数据的秒级甚至毫秒级查询响应。这些服务不仅支持传统BI报表,更是支撑了阿里双十一实时大屏、用户画像实时查询等高并发、低延迟的在线分析场景。
- 智能数据构建与管理:Dataphin:Dataphin是阿里数据中台理念的核心产品化输出。它超越了传统的数据开发工具,侧重于 “智能数据构建与管理” 。通过规范定义(如OneModel)、模型设计、数据萃取,它能将杂乱的原数据自动化、标准化地加工成可复用的数据资产(如主题域、业务过程、维度、指标),形成统一的数据服务层,从而消除数据孤岛,保证数据口径一致,极大提升了数据产出的效率与质量。
- 全链路数据服务与Serverless化:阿里云上的数据处理服务正朝着全链路、Serverless化发展。用户无需关心底层集群的部署、运维和扩缩容,只需关注业务逻辑和SQL编写。例如,Serverless版MaxCompute、Flink全托管服务等,实现了完全按使用量计费,资源秒级弹性。这降低了企业使用大数据技术的门槛,让数据处理能力像水电一样随取随用。
- 数据与AI的深度融合:数据处理系统不仅是数据的“搬运工”和“加工厂”,更是AI的“燃料库”和“试验场”。阿里将机器学习平台(PAI)与数据处理平台深度集成,支持在数据仓库内进行模型训练与推理(如MaxCompute ML),实现了数据与智能的闭环。数据处理的产出可以直接用于模型训练,而AI模型(如智能数据分类、异常检测)又反过来提升了数据治理的自动化水平。
三、 启示与展望
从阿里内部产品的演化可以看出,现代海量数据处理系统的设计精髓在于:以分层解耦获得弹性与灵活,以流批一体和湖仓一体实现计算与存储范式的统一,最终通过产品化、服务化的方式,将复杂的技术能力转化为业务人员易于理解和使用的生产力工具。
随着数据规模继续膨胀、实时性要求更高、应用场景更多元(如IoT、元宇宙),数据处理系统将继续向更实时化、更智能化、更一体化的方向演进。云原生、存算分离、异构计算、数据自治等将成为关键创新点。而核心目标始终如一:让数据价值的提取变得更简单、更高效、更普惠。阿里的实践为整个行业提供了宝贵的架构范本与创新思路,其“将能力服务化,将服务产品化”的理念,正是技术驱动商业成功的典型写照。