在数据驱动决策的时代,字节跳动作为全球领先的科技公司,面临着海量、异构、实时数据处理带来的巨大挑战。传统的大数据架构在资源利用率、弹性伸缩和运维效率上逐渐显现瓶颈。为此,字节跳动开启了大数据处理服务的容器化之旅,旨在通过云原生技术重构数据处理基础设施,实现更高效、更敏捷的数据服务能力。
一、背景与挑战:为何选择容器化?
字节跳动的大数据生态涵盖批处理、流计算、机器学习等多种场景,日均处理数据量达EB级别。原有的基于物理机或虚拟机的集群管理模式,存在资源隔离性差、部署缓慢、环境不一致等问题。特别是在应对突发的业务流量或快速迭代的数据产品时,资源调配往往滞后,成为业务创新的制约因素。容器化技术,以其轻量、可移植、快速启动的特性,成为解决这些痛点的关键路径。
二、核心构建:数据处理服务容器化架构
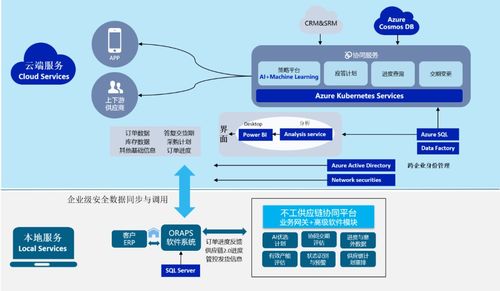
字节跳动的大数据容器化实践并非简单地将应用装入容器,而是从底层基础设施到上层应用的全栈重构。
- 统一资源调度平台:基于Kubernetes构建了大规模、高可用的集群管理系统,将计算、存储、网络资源池化。通过自定义调度器,优化了大数据任务(如Spark、Flink作业)的资源分配策略,支持优先级调度、抢占式调度,确保关键任务的资源保障。
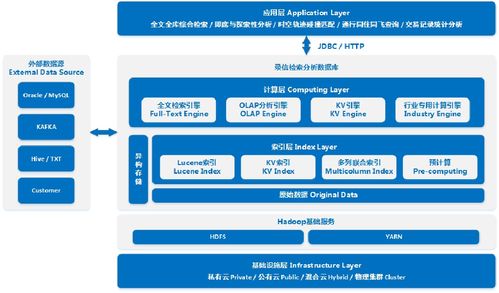
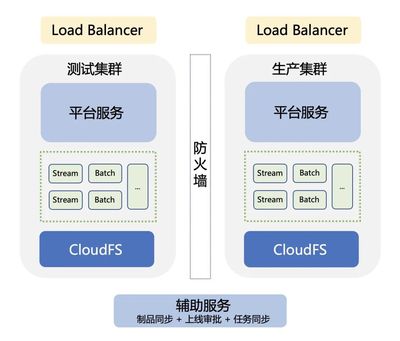
- 存储与计算分离:采用存算分离架构,将数据持久化存储在分布式文件系统(如HDFS)或对象存储中,而计算任务则在无状态的容器中运行。这种架构不仅提升了资源的弹性伸缩能力,还降低了存储成本,使计算节点可以根据负载快速扩缩容。
- 容器化数据服务组件:将Spark、Flink、Presto等大数据计算引擎,以及Kafka、RocketMQ等消息中间件进行深度容器化改造。通过定制Docker镜像,封装了统一的运行时环境、依赖库和监控代理,确保了任务环境的一致性,并简化了部署流程。
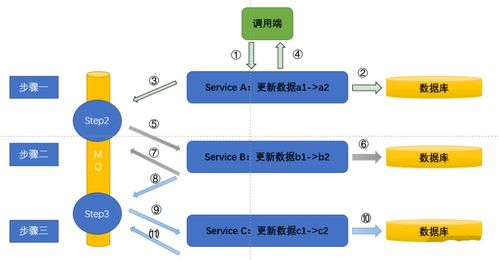
- 服务网格与网络优化:在容器化环境中,大数据组件间的网络通信至关重要。字节跳动引入了服务网格技术来管理服务发现、负载均衡和熔断限流,同时通过CNI插件优化网络性能,减少数据传输延迟,满足流式计算等低延迟场景的需求。
三、落地实践:关键技术与成效
在落地过程中,团队攻克了多项技术难关:
- 大规模集群管理:通过分级管控和联邦集群技术,管理了数万节点的Kubernetes集群,实现了跨地域、跨可用区的资源统一调度。
- 状态化服务管理:对于有状态的数据服务(如HBase),设计了基于Operator的自定义控制器,实现了自动化部署、扩缩容、备份恢复,提升了运维自动化水平。
- 性能与成本平衡:通过细粒度的资源配额管理和混部技术,将在线服务与离线大数据任务混合部署,大幅提升了整体资源利用率,降低了硬件成本。
- DevOps与CI/CD:建立了完整的大数据服务CI/CD流水线,实现了从代码提交到镜像构建、测试、发布的自动化,将新功能上线时间从数天缩短到小时级别。
实践成效显著:资源平均利用率提升超过50%,任务启动时间从分钟级降至秒级,集群运维人力成本下降约30%。更重要的是,容器化平台为数据处理服务赋予了极致的弹性,能够轻松应对抖音、今日头条等产品的流量洪峰,支撑了A/B测试、实时推荐、广告分析等核心业务的快速增长。
四、未来展望
字节跳动的大数据容器化实践已从探索阶段进入深化应用阶段。团队将继续探索Serverless大数据架构,进一步实现计算资源的按需分配和自动伸缩;结合AI技术实现智能调度与故障预测,推动数据处理服务向更智能、更自治的方向演进。这一历程不仅为字节跳动自身构建了强大的数据引擎,也为行业提供了大规模数据处理容器化的宝贵经验与范式参考。